Une Méthode pour tester des réseaux vulnérables
- Share
- Share on Facebook
- Share on LinkedIn
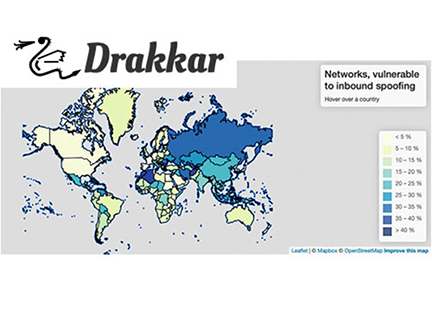
L'équipe DRAKKAR du LIG a conçu une méthode pour détecter si un réseau filtre le trafic entrant par l'adresse IP source. L'absence d'un tel filtrage ouvre des possibilités aux attaquants d'effectuer des attaques de type DDoS ou l'empoisonnement des caches DNS
La méthode consiste à envoyer des paquets contenant des requêtes DNS portant sur le nom que nous contrôlons, à chaque hôte de l'Internet avec une adresse IP source usurpée.
Si notre paquet atteint un serveur DNS local configuré pour accepter les requêtes de son réseau interne, il effectue la résolution DNS en contactant notre serveur DNS ce qui démontre que le réseau n'effectue pas de filtrage.
L'analyse de l'espace d'adressage IPv4 montre que près de la moitié de tous les systèmes autonomes routables (32 755 sur 66 978) étaient à l'origine de requêtes usurpées. Ils correspondent à 197 608 préfixes ou 938 472/24 réseaux IPv4. L'analyse de réseaux IPv6 révèle 4 766 AS, 6 873 préfixes BGP et 7 698/40 réseaux IPv6, vulnérables à l'usurpation d'adresse IP entrante. De plus, nous avons identifié 4 251 189 résolveurs DNS fermés IPv4 et 103 012 IPv6.
Publications
- Maciej Korczyński, Yevheniya Nosyk, Qasim Lone, Marcin Skwarek, Baptiste Jonglez, and Andrzej Duda. March 2020. Don’t Forget to Lock the Front Door! Inferring the Deployment of Source Address Validation of Inbound Traffic. In ACM Passive and Active Measurement Conference. Springer, 107–121.
- Maciej Korczyński, Yevheniya Nosyk, Qasim Lone, Marcin Skwarek, Baptiste Jonglez, and Andrzej Duda. 2020. The Closed Resolver Project: Measuring the Deployment of Source Address Validation of Inbound Traffic. arXiv:2006.05277 [cs.NI]
- Share
- Share on Facebook
- Share on LinkedIn